Deploying a ComfyUI Workflow on a Serverless Runpod Worker
⚠️ Disclaimer
This is a dated post, and currently the best way of implementing what is described here is in this repo. I'm keeping this, as it might be useful for context.
About two months ago, I started working on a project where I needed to run a ComfyUI workflow on a serverless platform (runpod.io). My goal was to use a combination of models, custom nodes, and workflows that originally worked on a basic ComfyUI server setup.
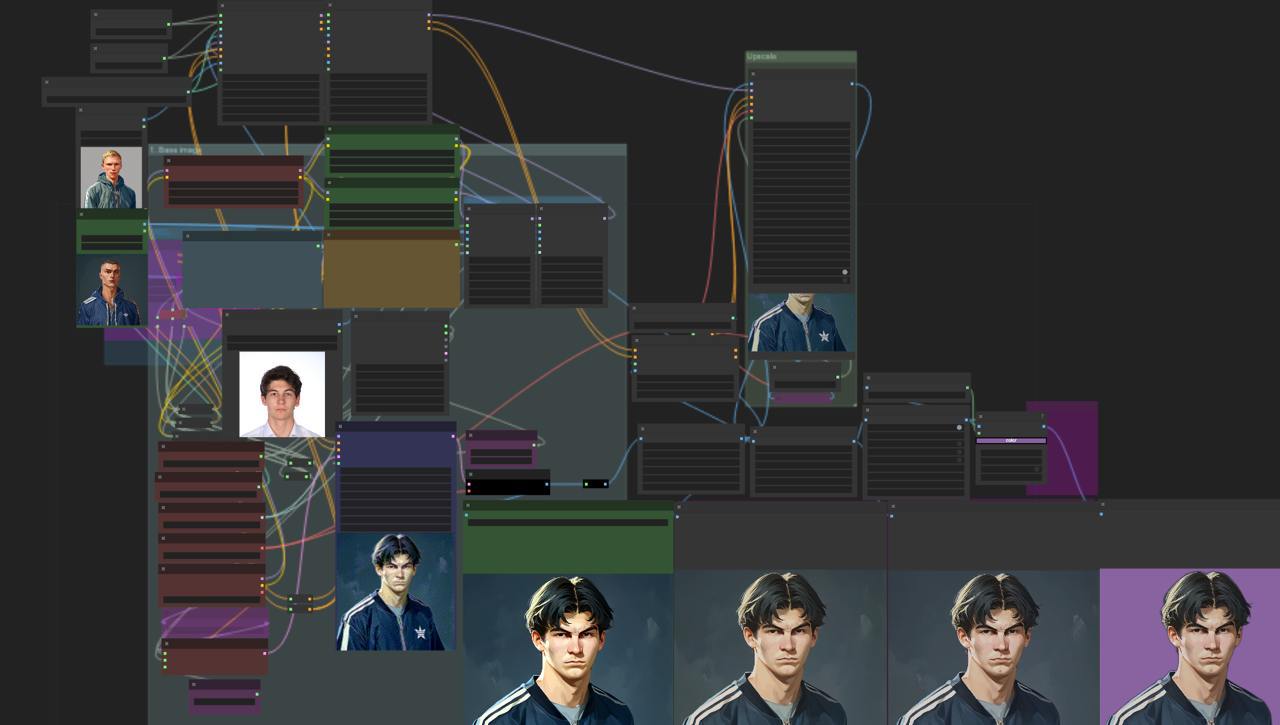
Step 1: Getting Reproducible Builds
The first challenge was setting up reproducible builds. This meant packaging all nodes and models (including custom ones) together. At first, I manually fetched every node and model using a shell script with wget commands. This allowed me to boot up an image from the Runpod registry, run the commands, and prepare the instance for usage.

But as one can imagine that isn't exactly efficient. The image sizes exceeded 50GB, taking a long time to install. To address this, I moved the models to a Runpod volume that could be mounted on any instance I boot up. Note that I couldn’t exactly do that with my custom nodes, since many of them require installing aditional python dependencies.
After installing the required models, I found that the versions of ComfyUI and ComfyUI-Manager in the Runpod image were outdated. To fix this, I added a small shell script to update them automatically.
It's about this time that I found out about ComfyUI-Manager's snapshot feature. It was a huge releif, since now, to boot up a new ComfyUI instance I could just start a new pod, update ComfyUI and ComfyUI-Manager with my shell script and load the snapshot.
Good, now that we have a working ComfyUI server we can start trying to make it work on a serverless endpoint.
Step 2: Docker
While looking for solutions on how to run ComfyUI on a serverless endpoint, I stumbled upon this project:
GitHub - blib-la/runpod-worker-comfy: ComfyUI as a serverless API on RunPod
These folks provided great documentation and a Dockerfile for building your own image. Perfect.
Now, before deploying our container on a serverless endpoint (which can be difficult to debug), let's try to run it on a simple pod. The config provides a SERVE_API_LOCALLY environment variable.
I added a Runpod volume and updated the paths in the extra_model_paths.yaml file.
A helpful pull request in the runpod-worker-comfy repository added support for loading custom nodes from snapshots, along with the required Python packages.
After taking a snapshot and updating the paths, I hit another snag: I couldn’t build the image locally on my M1 MacBook Pro. So, I rented a GPU instance from cloud.google.com. After several attempts, I finally built the image and pushed it to my DockerHub repository.
Before running it on a serverless endpoint , I tested the image on a standard Pod. If you’re doing this yourself, make sure to update the volume mount path to match the values in extra_model_paths.yaml.
The runpod-worker-comfy project conveniently provides an environment variable to simulate serverless endpoint behavior.

During testing, I discovered that insightface models couldn’t load from extra_model_paths.yaml. To fix this, I added a symlink to the start.sh file, pointing to my insightface models.
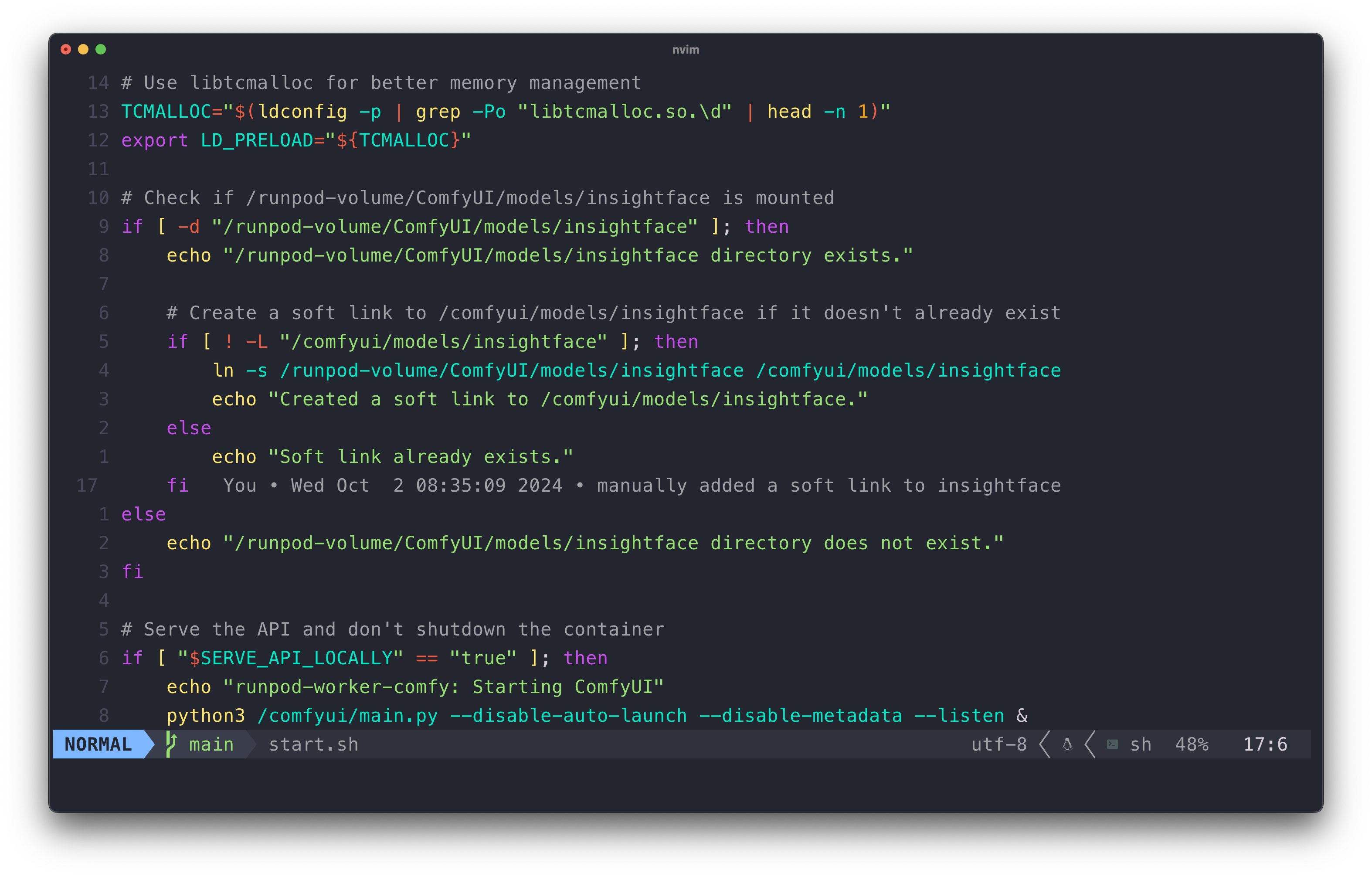
After this change, the workflow ran seamlessly.
Step 3: Deploying Serverless
Once the workflow was running, I deployed it to a serverless endpoint and added my S3 bucket credentials.
 *Redacted for privacy.
*Redacted for privacy.
However, there was an issue: the first few generations timed out.
runpod-worker-comfy provides an environment variable for polling max retries, but as noted in this issue, these variables fail to cast to integers when set via the Runpod configuration. I resolved this by hardcoding higher defaults and rebuilding the image (I know, it's less than ideal).
Error waiting for image generation: '<' not supported between instances of 'int' and 'str'
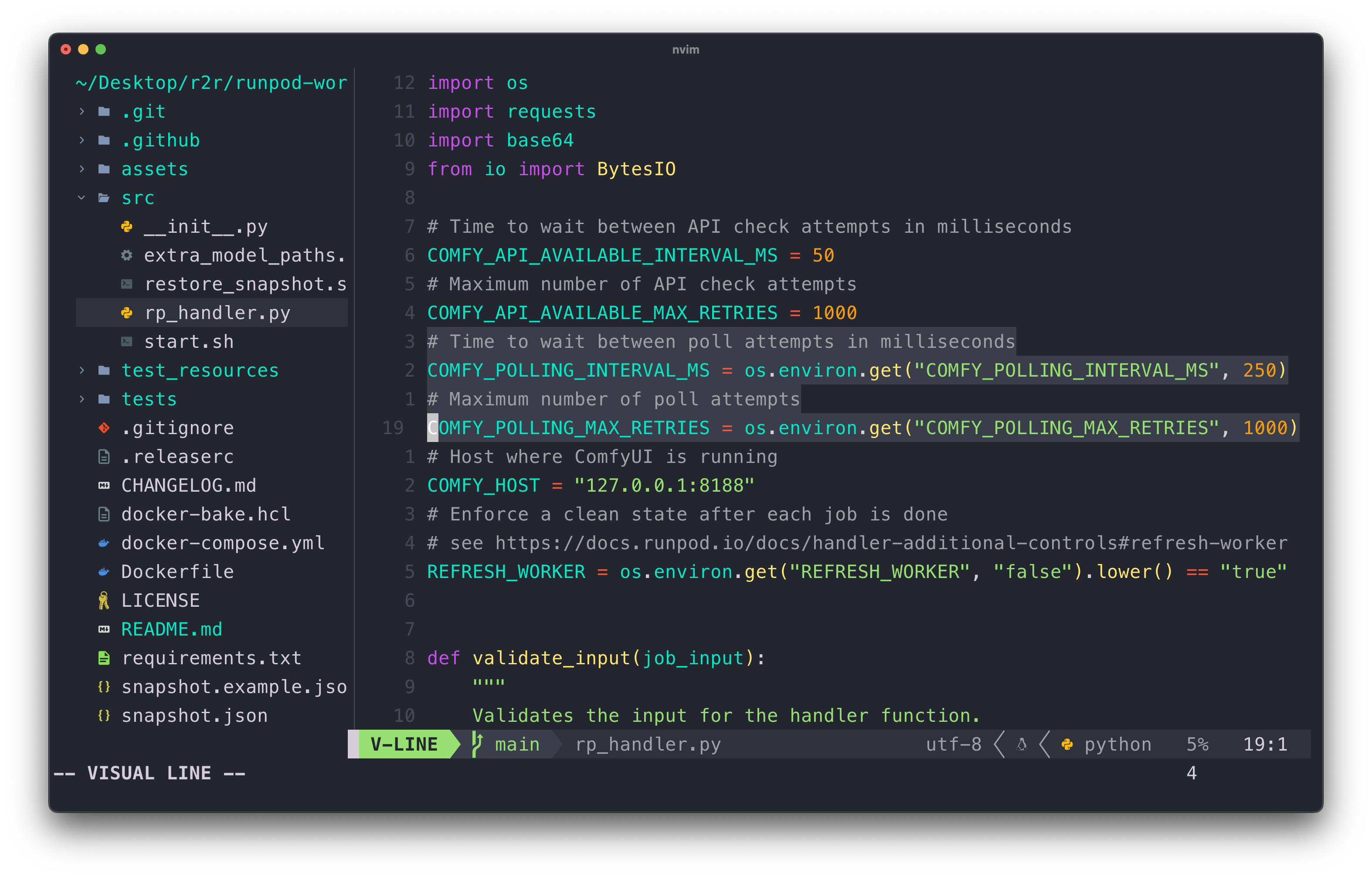
Eventually, it worked… kind of!


Backend
With the Runpod endpoint set up to boot an image on request, generating output was possible—but impractical. Each time I wanted to generate an image, I had to push a large JSON file to the /run endpoint, like this:
To streamline this, I wrote a simple Flask REST API. It includes an upload endpoint to send the image to S3 and a generate endpoint that:
- Passes the source image to GPT-4o for a basic description of the person (needed for the workflow).
- Adds custom parameters like background color, aggressiveness, and body complexity.
- Builds the payload and forwards the request to the Runpod serverless endpoint.
This resulted in a clean endpoint for uploading images with generation parameters and a status endpoint for updates.
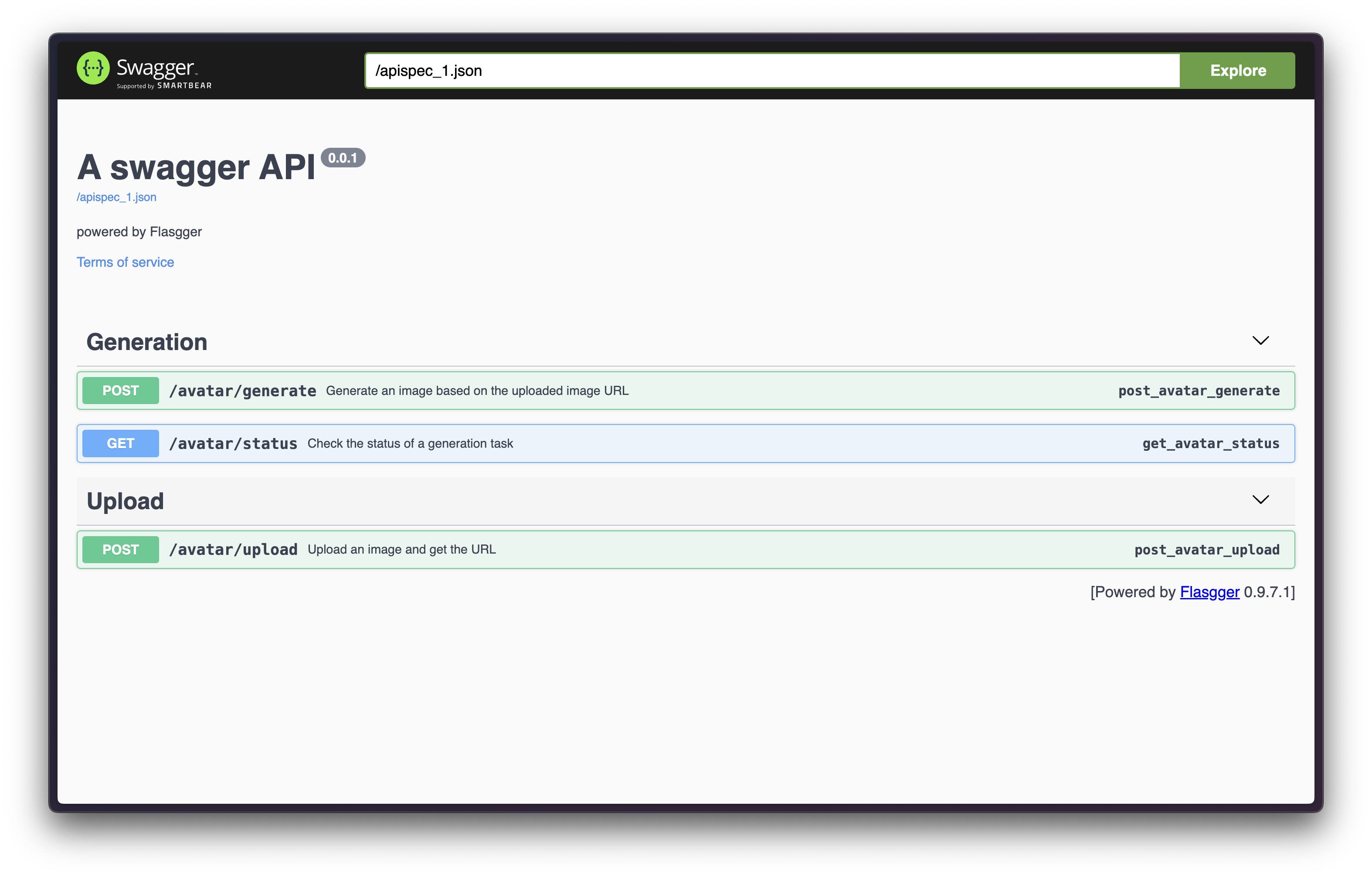
User Interface
Finally, I wrapped the API into a React-based user interface.

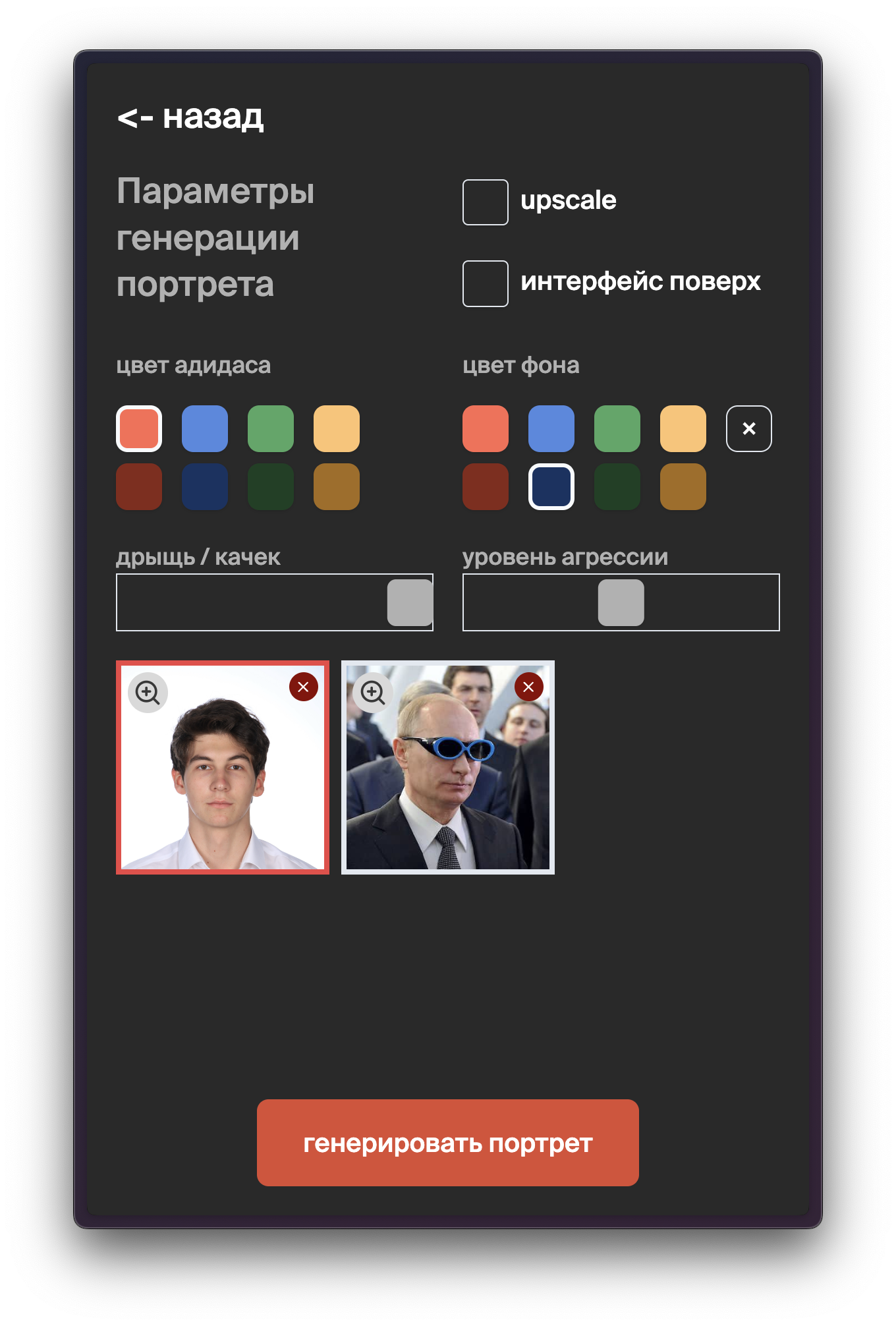
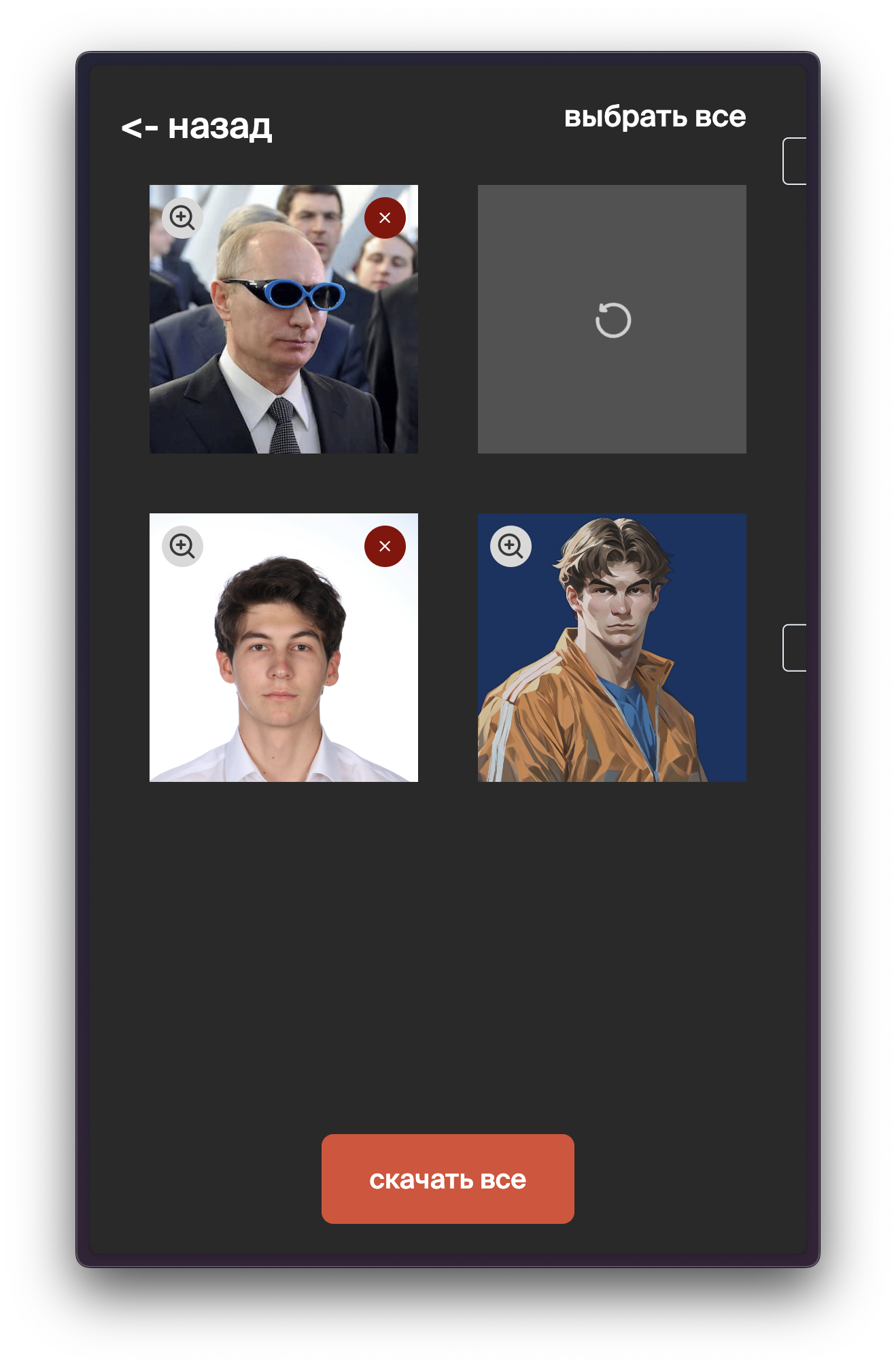
With some React magic and long polling, I created a neat interface to manage the serverless endpoint and run concurrent generations.
Overall, setting this up was a fun challenge, but there’s still plenty to improve, including cleaning up the code. I hope this helps anyone attempting something similar have an easier time!